September 28th, 2021
Image sourced by unsplash.com
Data stewardship can unlock the societal value of data, empower individuals and communities while safeguarding rights
The Data Economy Lab conceptualizes stewardship as a broader paradigm that pushes the envelope of data governance beyond matters of compliance. Through stewardship, we can envisage new ways to prioritize and embed individual and collective forms of empowerment, agency, and participation in the data economy.
In action, we see stewards as neutral, transparent ‘data intermediaries’ that tend to lie between data generators, holders, and requestors. We firmly believe that these types of institutions will play a large role in rebalancing power in the data economy and helping individuals and communities in navigating and negotiating better on their data rights.
Over the past 18 months, we’ve studied existing and emerging stewards operating across different sectors to understand their purpose, governance structures, and choices they make to engage their beneficiary users. We’ve built this tool by keeping in mind that there is no one-size-fits-all solution – but also recognize, there are foundational elements that can help build a “good steward”
Going forward, we believe it will be critical to building robust data stewardship ecosystems of different stewards/data intermediaries – these will be tailored in part, to the sector, use-case, and regulatory requirements of that particular region. Within this rich ecosystem, entities will also vary in the way they are structured, the roles they play, and how they interact with stakeholders in the data economy.
This tool aims to surface and make these choices more visible – we hope this serves as a resource to propel further discussions and application of stewardship on the ground.
Data Stewardship: A part of the puzzle to rebalance the data economy
While Stewardship is beginning to gain greater visibility in theory, it remains a relatively nascent concept in practice. To better understand this trajectory on the ground, we’ve visualized this through the Data Stewardship Ladder (see Figure 1 below) to better understand what the journey to becoming a steward may look like. While not always linear, we’ve observed that most organizations start their journeys at Step 01 in the figure below.
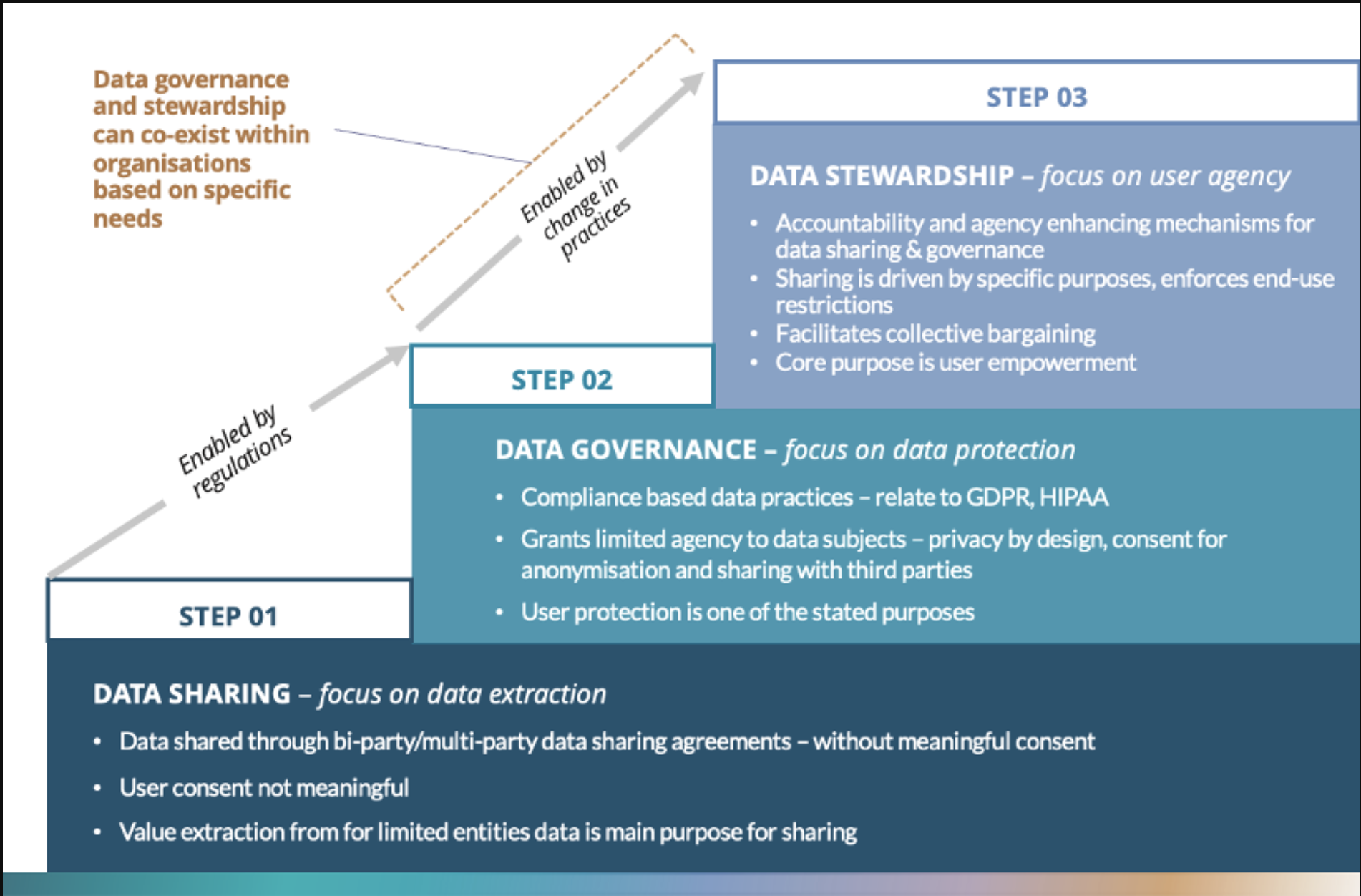
Figure 1: Data Stewardship Ladder
Over the past 5 years, regulations like GDPR have been a driving force in instituting greater privacy controls and outlining a system of rights for individuals – which has largely enabled organizations to traverse to Step 02.
Despite its significance, however, compliance-focused data governance practices fall short of granting ‘data subjects’ or generators with the meaningful agency in the digital economy. This leaves us as individuals or communities with few avenues to participate in the data economy. Where possible, this is usually limited to accepting cookies, providing consent, or submitting a request for a copy of data.
We believe deeper and more meaningful modes of participation and representation are required and traversing to stewardship (Step 3) is a useful paradigm to explore this.
This sentiment has also been echoed within the ecosystem, where there is a growing momentum to find solutions to rebalance the data economy. These efforts have come from communities, technologists, civil society organizations, and businesses across the world who, like us, are finding new ways to resist data extraction and monopolization, and instead build responsible and equitable systems of data stewardship.
Increasingly, we’ve seen these very organizations act as stewards, help communities negotiate better on their data rights, help empower individuals to have greater control over data decision-making, and incentivize organizations to share data more readily.
The need we’ve identified
Over the last 2 years, through our in-depth qualitative study that documented practices of over 50+ stewards across 5 different sectors, we learned that establishing or transforming into a steward is complex and often not prioritized due to a lack of knowledge, resources, and capabilities. It was also evident that organizations that are committed to these efforts often must build these institutional processes from scratch. Many of the practitioners we interviewed also surfaced the need to facilitate ecosystem conversations and build networks for collaboration & problem-solving.
Important work is already underway in the ecosystem, we are also excited to be leading these efforts along with several other important organizations in space. Some of these efforts have been captured in the illustration below, but this list is by no means exhaustive as we recognize this space will continue to evolve.
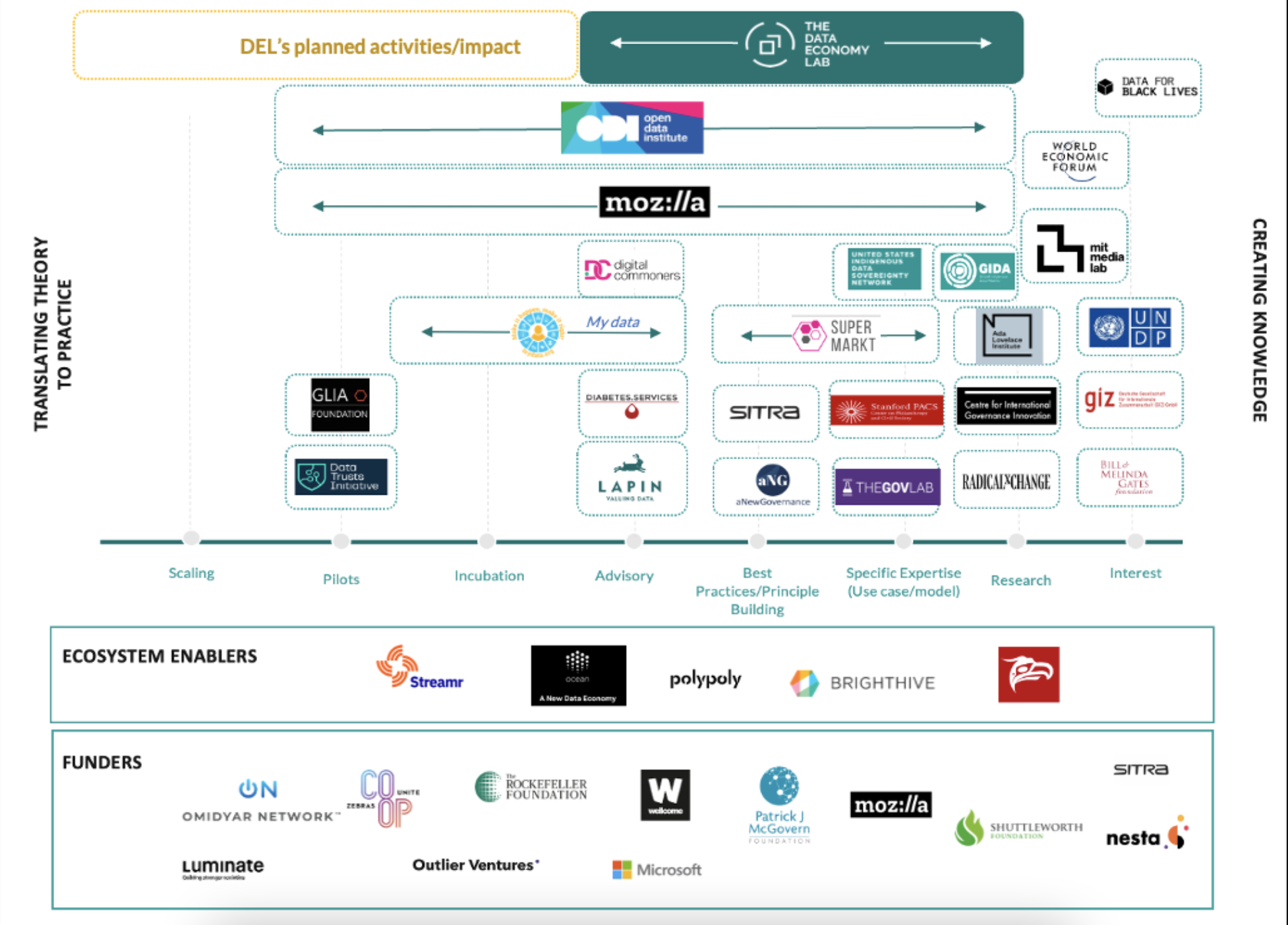
Figure 2: Stewardship Ecosystem
What is the Data Economy Lab’s Approach?
Stewardship holds great promise for improving systems for data collection, storage, exchange, and negotiation, but this can only be meaningful if community-centrism and rights are at the heart of its design, deployment, and evaluation.
Guided by this vision, our work at the Data Economy Lab follows these broad principles:
Rooted in practice
To ensure our work reflects on-ground realities, our methodology is oriented around providing a platform for practitioners to share best practices. We are also focused on identifying new ways stewardship can be translated from theory to practice and both advocate for and drive pilots to understand how this may differ across use-case, region, and other factors.
Multidisciplinary
Shaping equitable data futures and identifying how to better empower communities with a greater agency requires various types of expertise, knowledge, and general representation of multiple voices – both technical and community-oriented. Through our research and collaborations with partners, we aim to incorporate varying perspectives and ensure our output is similarly accessible to a broad set of stakeholders.
Collaborative
We continue to draw from and add to an emerging body of work driven by organizations like Mozilla Foundation’s Data Futures Lab, Ada Lovelace Institute, the Open Data Institute among others. We hope to continue exploring the application of data stewardship with thought leaders and practitioners on the ground – from the private sector, civil society, and public sector
Inclusive
The inequities of the data economy disproportionally affect marginalized and underserved communities across the world. In our work, we aim to surface these realities and spotlight voices from these communities driving forward these efforts.
Accessible
We aim to disseminate actionable insights and findings that can be engaged with or applied by individuals, community leaders, or organizations. We constantly are finding new avenues to put across these learnings – through guides, tools, playbooks, and multimedia formats.
What has our journey been like so far?
Phase I
Building the Stewardship Model Taxonomy
We started by carrying out an in-depth survey of the ecosystem to build the first report of its kind that acts as a taxonomy of data stewardship models – these include but are not limited to data trusts, exchanges, account aggregators, etc.
Mapping out the ecosystem
Keeping in mind regional and use-case/sectoral diversity, we proceeded to create a repository of over 100+ organizations that qualify as ‘stewards’ across sectors like health, agriculture, smart cities, etc
Establishing case studies and exploring use-case specific stewards
As the landscape of data intermediaries has rapidly evolved since the creation of our initial repository, we continued to identify and map emerging stewards and add to our repository with an additional 123 organizations or initiatives.
We learned early in our research that:
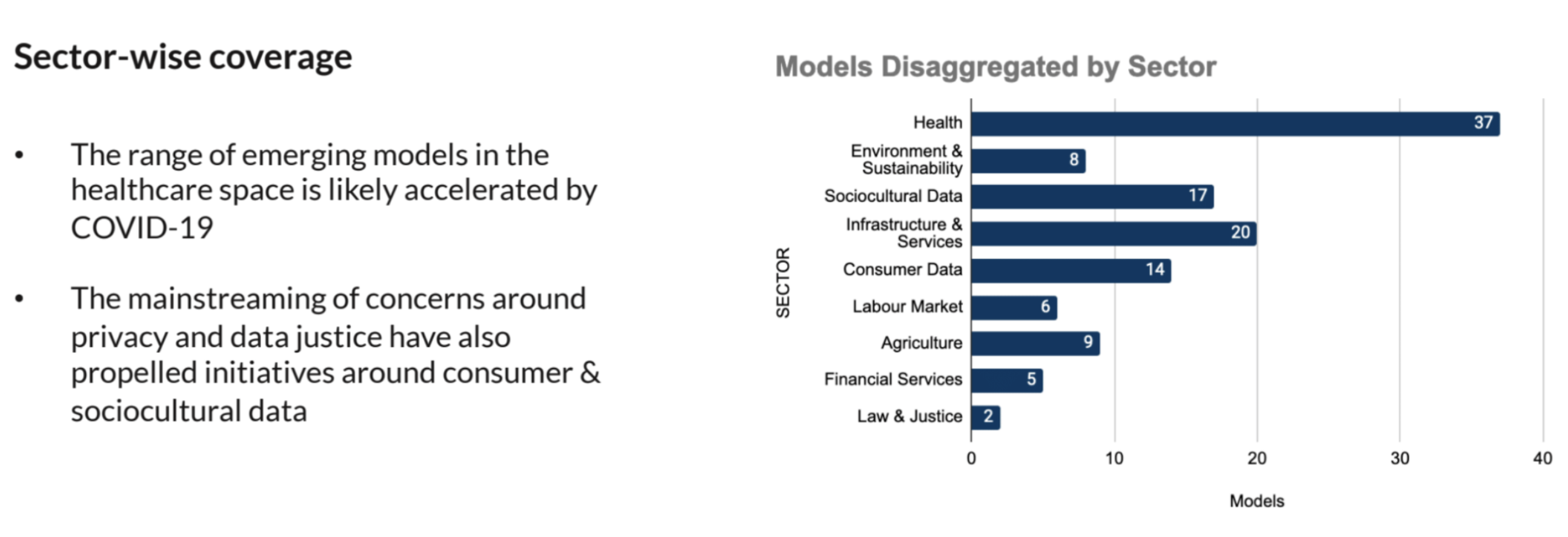
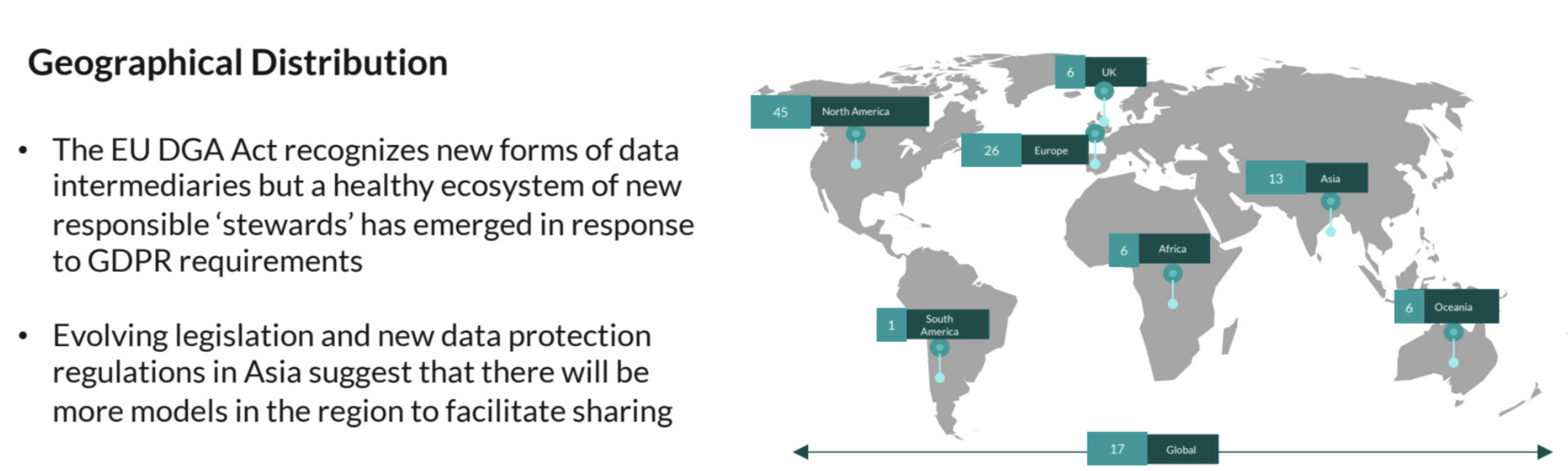
Phase II
In our initial conversations with stewards, we noticed the variation in how stewards were operationalized even within sectors and were keen to understand the reasoning behind some of these choices. We realised that a range of other factors may influence these decisions. To learn more about the journeys of practitioners in establishing or scaling their stewarding entities, and deepen our understanding, we engaged in a robust case-study-driven analysis.
Methodology
Recognizing the complexities of stewardship – both in how it is defined and enacted, we wanted to map these complexities, through a qualitative approach. This involved the steps illustrated in figure 3 below:
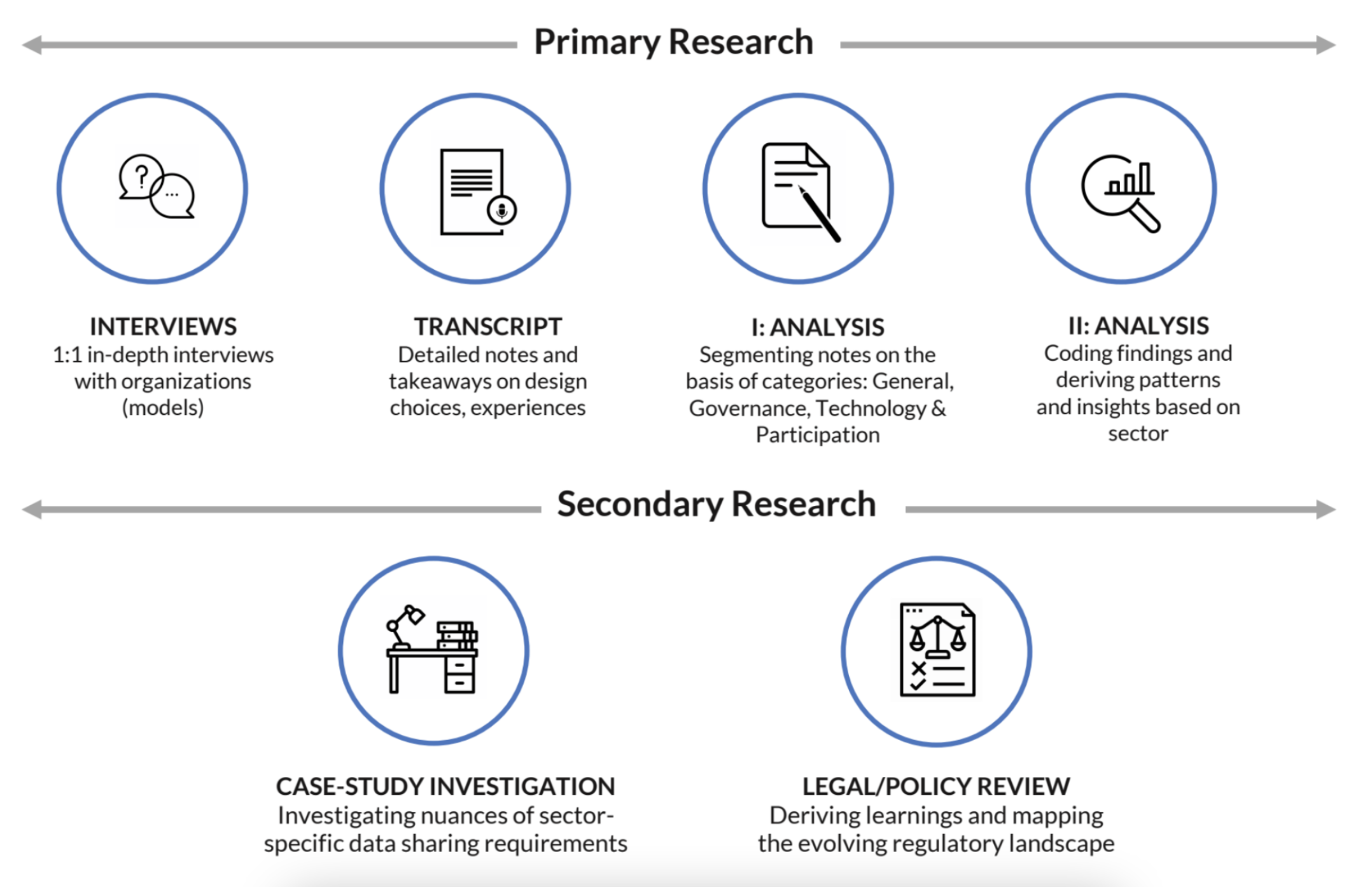
Figure 3: Data Economy Lab’s Methodology for Phase II
Interviews
The Data Economy Lab team reached out to 85 organizations for interviews. 50 organizations responded and we set up in-depth interviews with either the founders of these companies or those on the leadership team. Accounting for COVID-19 restrictions and the global presence of organizations, all interviews were conducted virtually through the use of platforms like Zoom, Google Meet, or Microsoft Teams.
Interviews were semi-structured and featured a combination of open-ended and closed-ended questions that aimed to capture the experience establishing the steward, purpose, and structure of its operation and challenges in scaling these efforts. Sample questions and themes have been included in Figure 4.
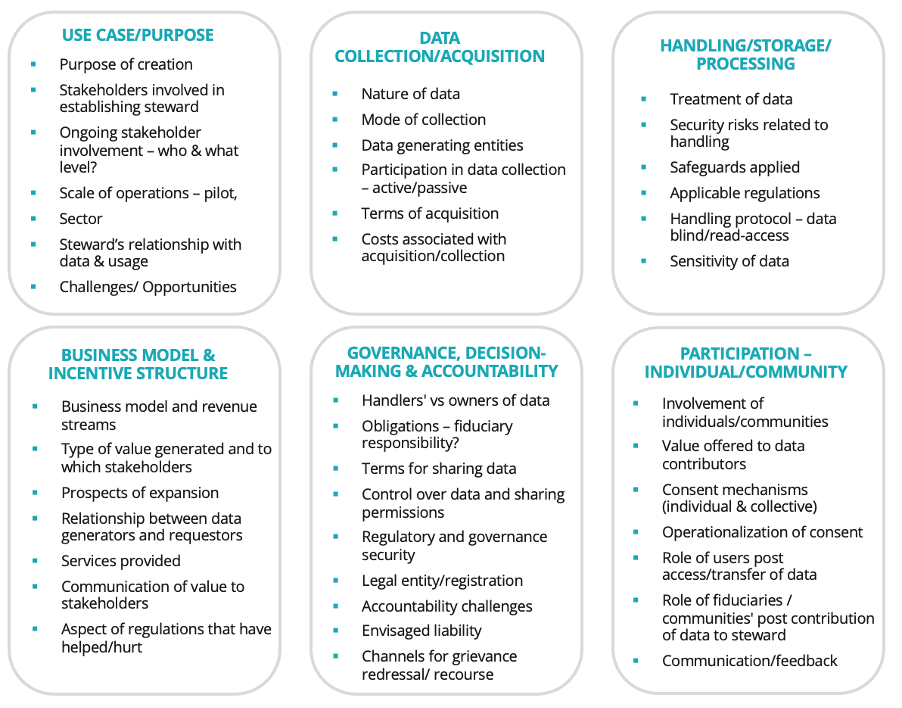
Figure 4: Themes and questions posed to ‘stewarding’ organizations
Transcript
Where interviewees consented, interviews were recorded, transcribed through the support of a tool, and corrected manually for errors. Where consent was not provided, detailed field notes were produced from the interview and supplemented with publicly available information on the organization.
I- Analysis
Through a primarily subjective lens, we identified patterns and common responses to questions and organized these under the categories listed above in Figure 4.
From the transcription, we summarized responses in an excel spreadsheet – a visual representation of this has been included in Figure 5
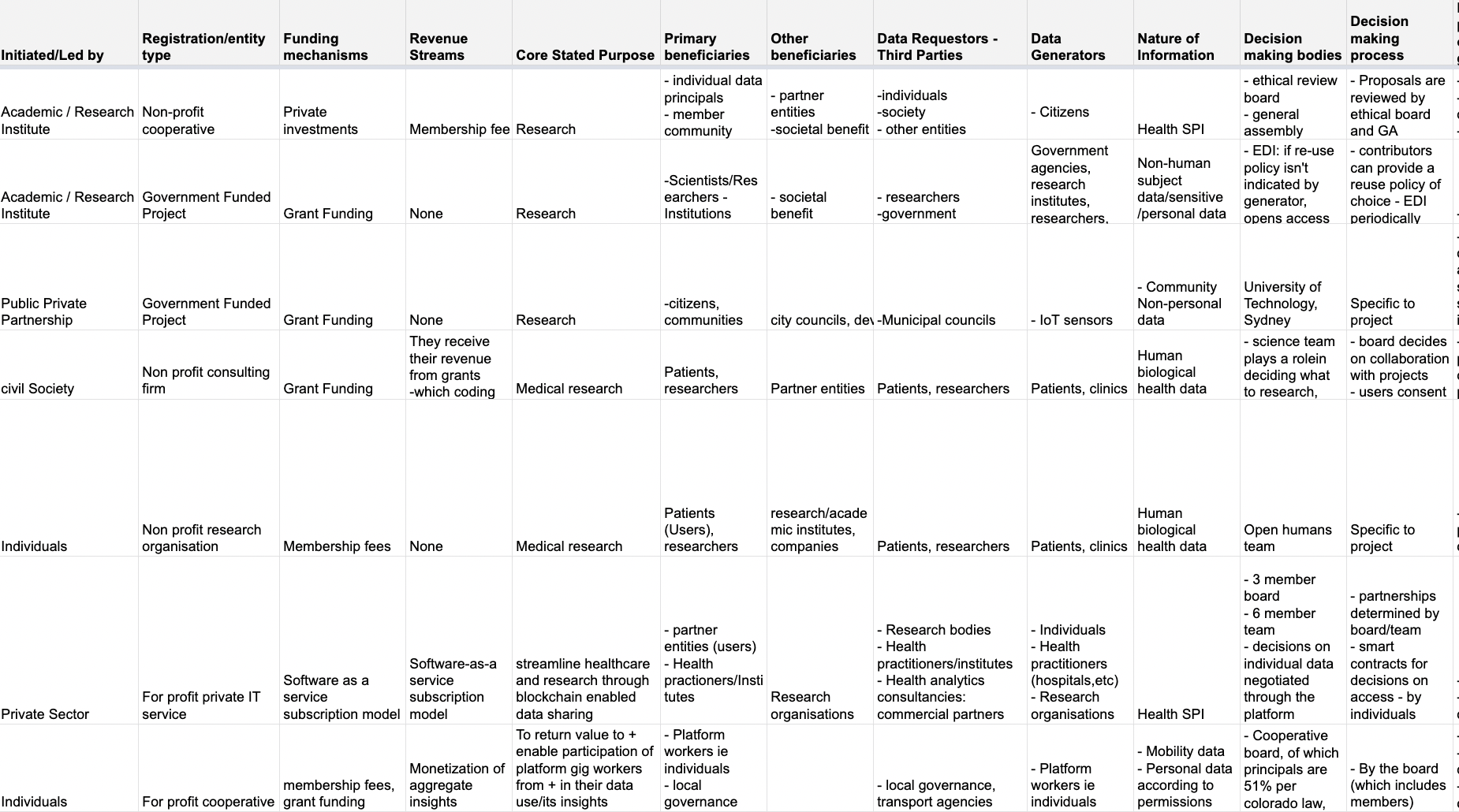
Establishing codes
Following this, to delineate and create a common vocabulary around some of these organizational choices and structures, our team collectively created a set of codes. These codes helped us define both objective and subjective criteria that are in many ways foundational to understanding stewarding roles, structures, and choices. We drew explanations from our existing research as well as secondary material relating to data governance. A sample of these codes has been included in Figure 6 below.
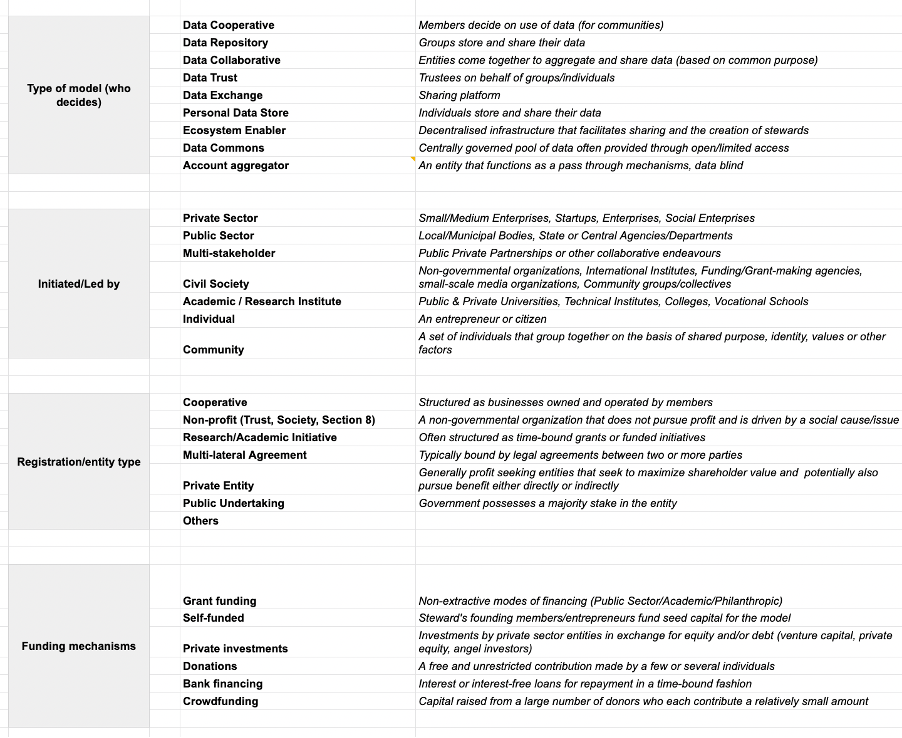
Limitations
Our research has relied solely on in-depth interviews with practitioners of models and secondary desk studies. The perspective this offers, while important, does not necessarily capture the experience of the user or ‘data generator’/provider. In a similar vein, the outcomes of the research are also aligned to a limited set of 46 case studies, many of which are located in the global north. Additional research will only improve the practices and recommendations that form the foundation of any interactive tool or guide.
The DEL team also recognizes that while Data Trusts have been included as one of the types of data stewards, we have not classified any of the models in our latest case study repository under this typology. The inclusion of this model we believe is still necessary and the team will continue to nuance this analysis as the ecosystem evolves.
Launch of the Stewardship Mapper
Recognizing this consolidated information may be useful to share broadly, we decided to release part of our analysis that captures and visualises the codes we defined at the start of our analysis. The stewardship mapper represents a variety of choices and sub-choices we felt would be best visualized through a partly interactive mind map tool.
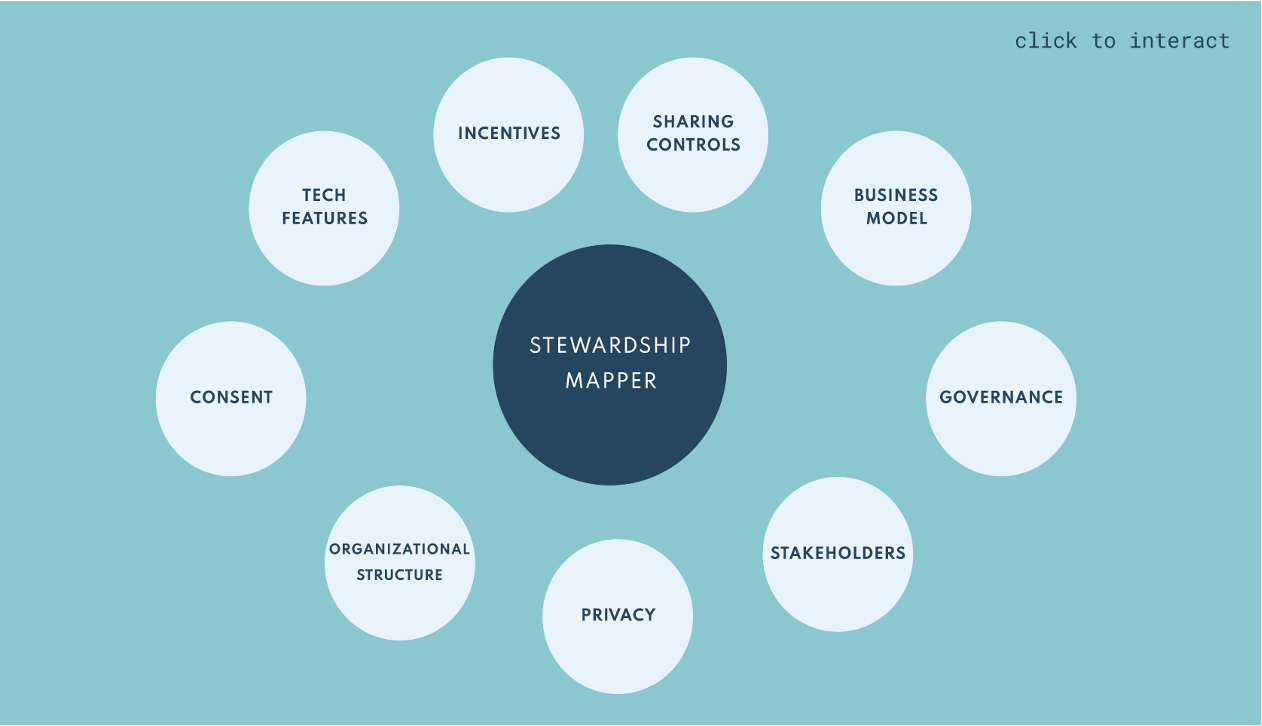
I- Analysis: Coding Interviews
Based on our generated codes, we streamlined our initial analysis from excel onto Airtable for greater clarity.
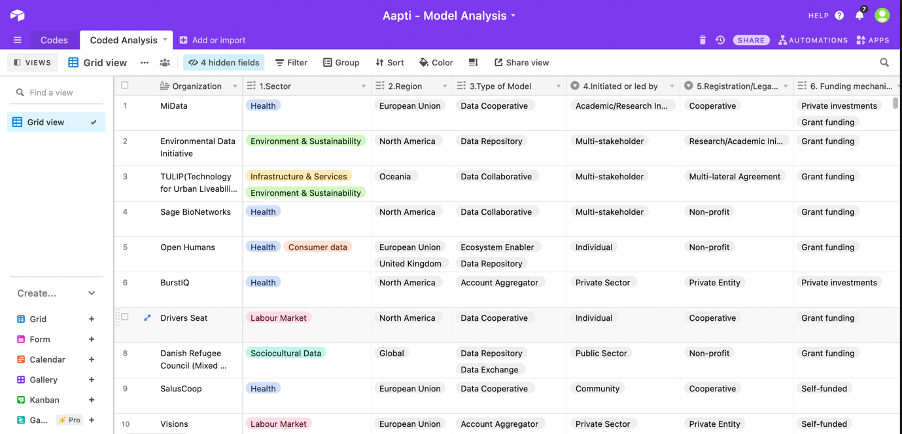
Query our database for insights and patterns
After cleaning up our final database of coded interviews, we worked with a consultant who helped build a graph-based code. The rationale behind this was to find patterns of behavior within the data that we had gathered.
We started this by calculating correlation scores of various pairs of variable values. As an example, let’s say we do this for variables A and B. A has 5 values and B has 4. This will tell us what percent of the time each value of B occurred given any value of A. From these pairings, we looked at the significant correlations that show us trends in the space.
From this code, we were able to identify the correlation between variables. For instance, based on our dataset :
If the level of third-party access is “Access no transfer”, 72.7% of the time the data requestors are “Researchers/Academics”.
83.3% of all organizations initiated or led by an “Academic/Research Institute” are funded through “Grant funding”.
100% of organizations initiated or led by the “Public sector” are funded through “Grant funding”.
If the revenue comes from a “Subscription Model”, 71.4% of the beneficiaries are “Partner Entities” – by which we mean B2B subscribers
In the instance that a “Non-profit” generates the data, the nature of the information is typical “Personal” and “Sensitive”
Phase III: Building the tool
Guided by our goal of accessibility, our vision was to make the outcome of our study as actionable as possible. As we had 46 case studies to draw from, we wanted to extrapolate these findings and share best practices and how they may align to a particular type of steward.
This way, the journey of a steward could be made more visible to organizations looking to transform into this kind of intermediary.
To make this actionable, we were keen to add a layer of interaction to guide users through various possibilities and design choices.
Our process of creating a stewardship related tool followed a few different steps:
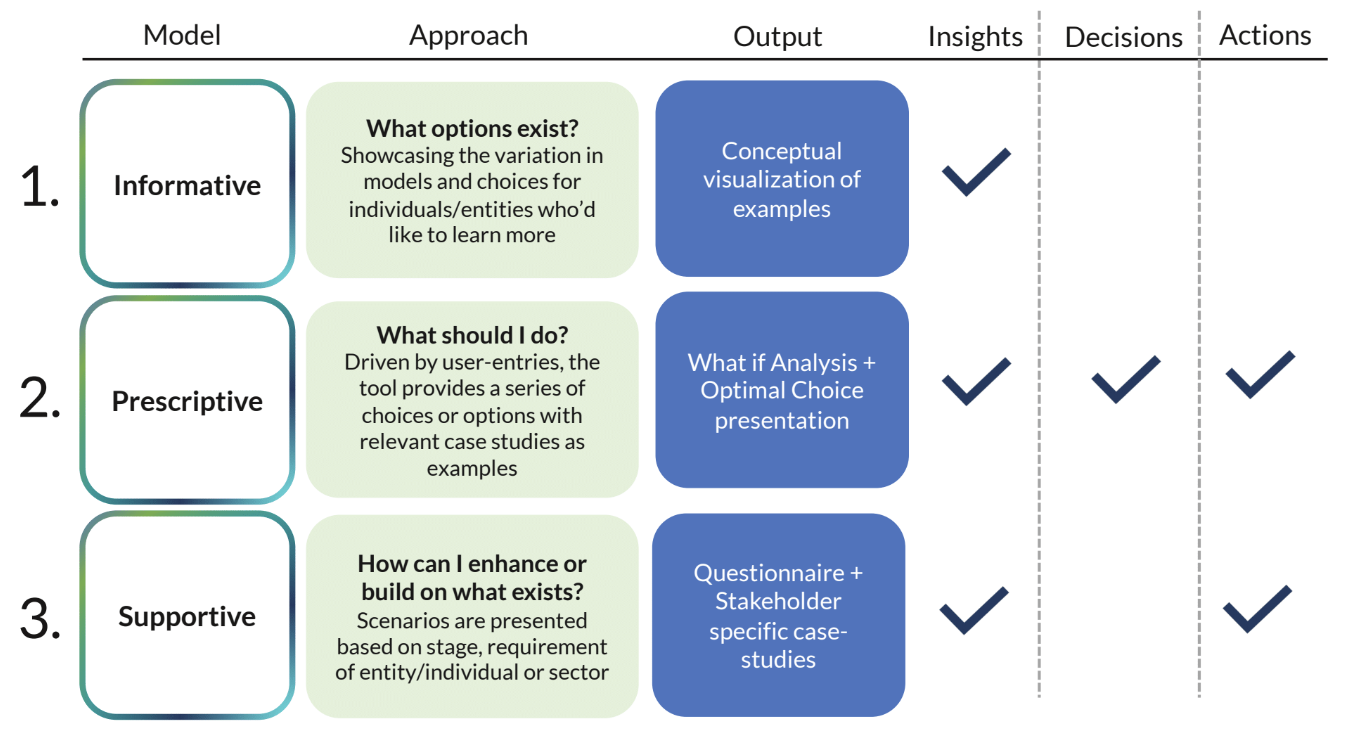
- Deciding on our approach and objective
We started by identifying approaches for the tool. Acknowledging that a prescriptive approach may dilute the complexities of data governance and stewardship, our goal was to keep the tool informative and supportive.
- Defining our target audience and identifying potential user groups
We decided early on that while user personas could guide the creation of the tool they will not structure suggestions, choices, or recommendations based on selected persona type. We imagine several different personas who may be interested in exploring the tool but felt that ‘Non-profits’ & Community-Based Organizations/Collectives may be the most relevant audience for our research.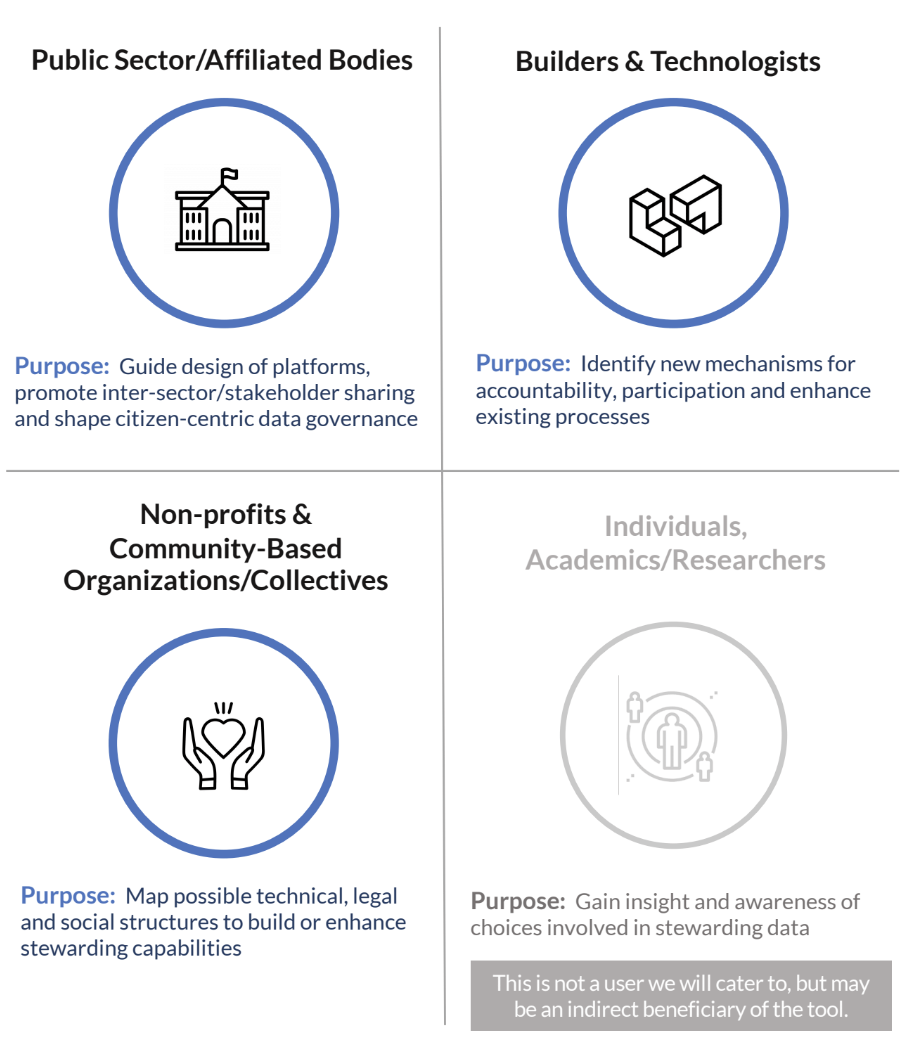
Figure 11: Defining our target audience and potential stakeholder groups
- Visualize the potential user journey for users
While arriving at data stewardship is not always a linear process, organizations may explore these concepts at different phases of their journey, it was important for us to map out what the varying “layers” of stewardship may look like. Based on this we charted a few samples of “user journeys”, where the data stewardship model was listed as an end goal or outcome of the stewardship journey.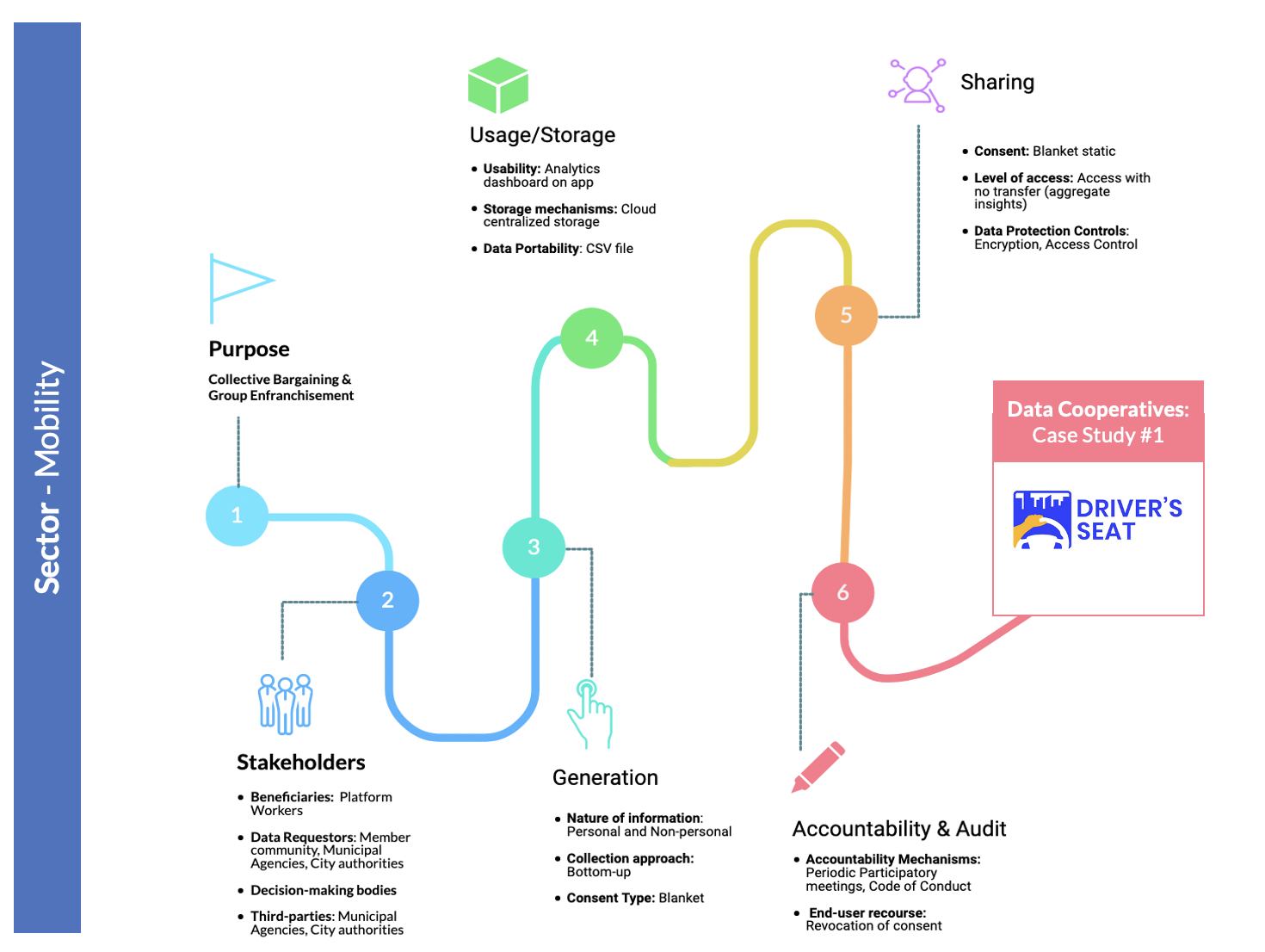
Figure 12: Sample User Journey with a case study
- Build a logic flow & data structures
Our intent with this tool was to make sure users could easily explore choices and view how these were associated with different data stewardship models. At the outset, we realized that presenting users with all of these models on a single screen would not make for an intuitive user experience. Instead, we attempted to partially gamify the experience, encouraging users to make a set of choices and be guided to various stewardship models on that basis.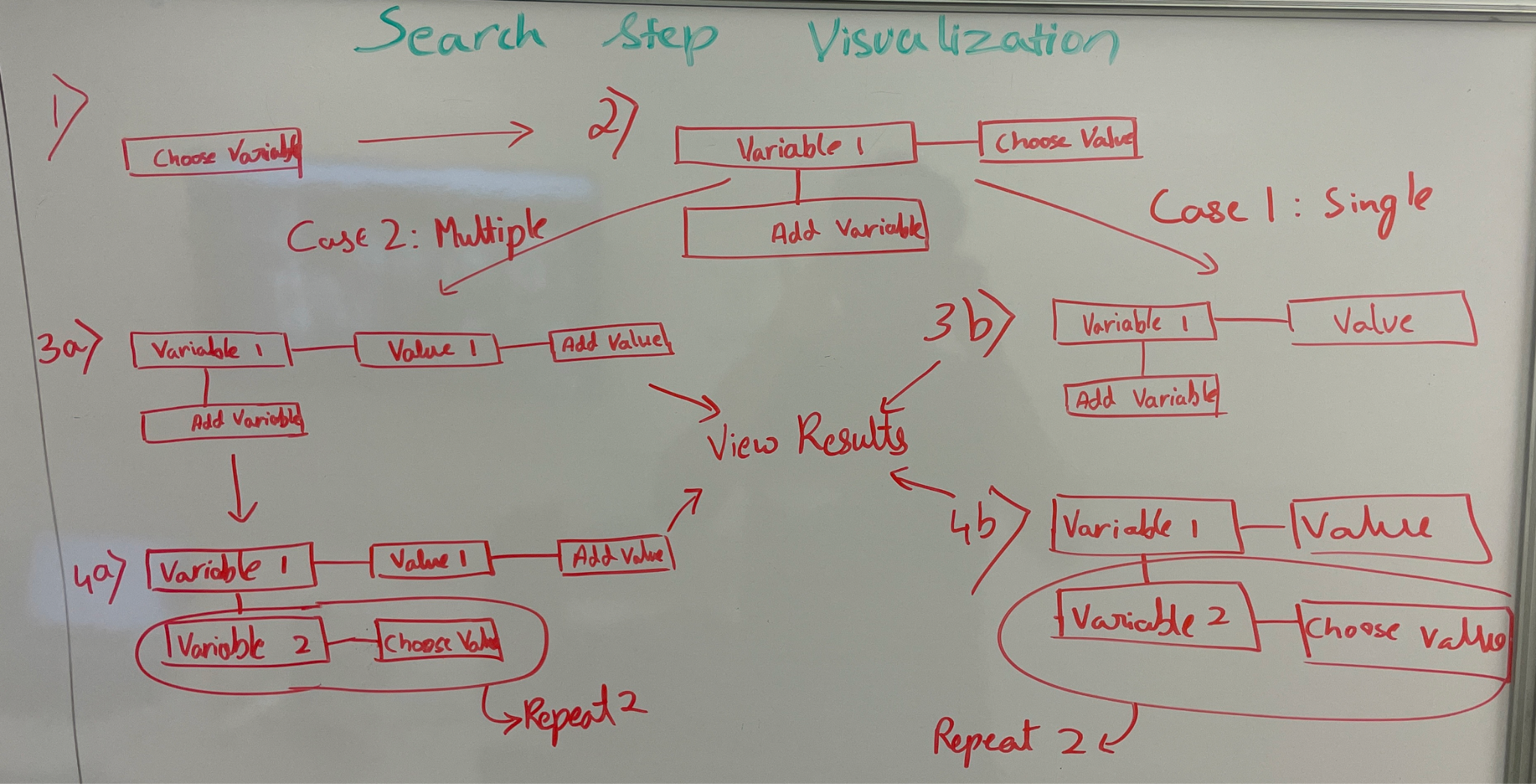 We started with using a co-occurrence graph on our dataset with the idea to keep pruning non-adjacent nodes every time a value was picked. We anticipated that this structure would be highly efficient as the number of nodes, which represent the total possible values for all variables, was extensive. However, realising we were working with a relatively small dataset of 46 case studies, we decided to go with a more classical SQL database.
We started with using a co-occurrence graph on our dataset with the idea to keep pruning non-adjacent nodes every time a value was picked. We anticipated that this structure would be highly efficient as the number of nodes, which represent the total possible values for all variables, was extensive. However, realising we were working with a relatively small dataset of 46 case studies, we decided to go with a more classical SQL database.
With this approach, we start with all values in this database and as the users pick a value for each variable, the options for the next would be limited by their previous choices. They would only see options that occur with their previous choices. To keep the process informative, we wanted to ensure that users are provided with details as to why a question is being asked and its significance. As users continue along this journey, their ability to choose options in each subsequent question continues to be limited until they are left with only one option (that matches with a corresponding type of data steward) left for every remaining variable.
At this point, the user has arrived at only one remaining type of data steward. If the user stops before reaching this point, the two most commonly occurring types of stewards are selected and presented to the user.
To ensure that we were not being overly prescriptive by only representing one matching data steward, we were keen to surface two models that matched with users’ choices and journeys. The way we technically achieved this was by picking the first option based on what the user chose – if there is only one choice based on the users’ choices, we start disregarding variables in the reverse order of selection till we get another type. This is how, no matter what, the system will give the user 2 options for them to view. This is an implementation of a technique called “fuzzy hamming distance”. It calculates the Hamming distance between the users’ choice and the closest incorrect answer by varying the number and location of the hamming vector components till that answer is found.
On choosing an option, the users get to read a description of that type of data intermediary and see the case studies that Aapti has compiled on organisations that are examples of that type of intermediary.
- Testing & Evaluation
Our goal is for the Stewardship Navigator to be an actionable tool for individuals, researchers, practitioners keen on building stewards and civil society organizations who are shaping citizen-centric systems of data governance. While this has been built based on our selected case studies – this does not aim to be prescriptive but rather hopes to raise critical inquiry and awareness about the facets of stewardship.As this is our first go at creating a tool of this nature, we are keen to ensure that it is accessible, useful, and reflects ground realities. Keeping this in mind, we hope to carry out a few phases of testing, evaluation, and cycles of incorporating feedback. As you experience our tool, we’d love to hear your thoughts on how user-friendly it may or may not be, what aspects you enjoyed and what remains to be covered. We look forward to continuing to iterate on this with this feedback and suggestions from the community.